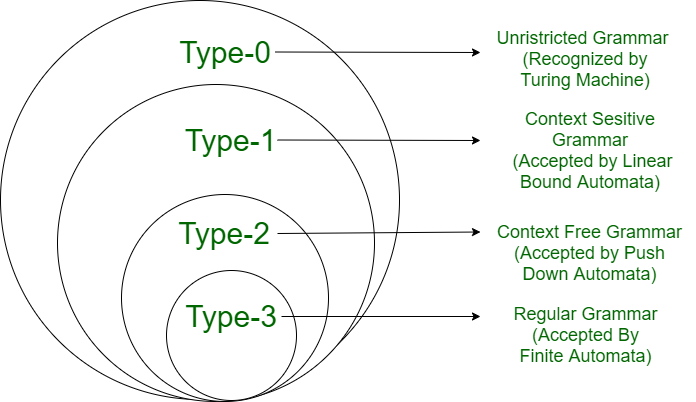
What is a Formal Language?
In everyday usage the word "language" conjures up images of grammar books, vocabularies, and conversations. In computer science and mathematics the term is given a precise, stripped-down meaning: a formal language is simply a set of strings drawn from a fixed alphabet.
An alphabet Σ is a finite, non-empty set of symbols (e.g., Σ = {0, 1} or Σ = {a, b, c}). A string over Σ is any finite sequence of symbols from Σ. The empty string is written ε. The set of all strings over Σ is denoted Σ*.
A formal language L over alphabet Σ is any subset of Σ*: that is, L ⊆ Σ*. The language may be empty, finite, or infinite.
Examples abound everywhere: the set of valid C programs is a formal language over the ASCII alphabet; the set of all binary strings of even length is a language over {0, 1}; even the empty set ∅ qualifies as a language (the language that accepts nothing).
Source
Regular Expressions
One of the most compact and widely-used ways to describe a language is the regular expression. Regular expressions appear everywhere — from command-line tools like grep and sed, to validation in web forms, to the internals of programming language compilers and interpreters.
A regular expression (regex) over alphabet Σ is defined recursively: (1) ε and any symbol a ∈ Σ are base regular expressions; (2) if R and S are regular expressions, so are R|S (union), RS (concatenation), and R* (Kleene star — zero or more repetitions). Nothing else is a regular expression.
The Three Core Operations
Union (R|S): Matches any string that belongs to language R or language S. For example, a|b matches the single-character strings "a" and "b".
Concatenation (RS): Matches any string formed by taking a string from R followed by a string from S. ab matches only "ab".
Kleene Star (R*): Matches zero or more strings from R concatenated together. a* matches ε, "a", "aa", "aaa", and so on.
(a|b)*— All strings over {a, b}, including the empty string.a*b— Any number of a's followed by exactly one b: b, ab, aab, aaab, …(0|1)*00— All binary strings that end with "00".a(a|b)*b— Strings that start with 'a', end with 'b', with anything in between.[0-9]+— (Extended regex) One or more decimal digits — a non-negative integer.
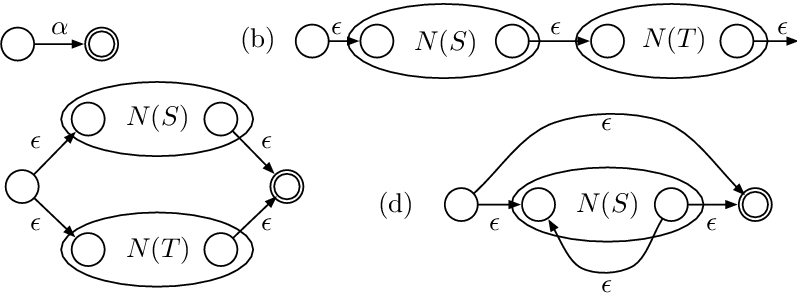
Image: Source
Finite Automata and Language Recognition
Describing a language with a regular expression tells us what strings belong to it. A finite automaton (FA) gives us a mechanical procedure to decide membership: feed a string in, watch the machine run, and observe whether it ends in an accepting state.
A DFA is a 5-tuple M = (Q, Σ, δ, q₀, F) where: Q is a finite set of states; Σ is the input alphabet; δ: Q × Σ → Q is the transition function; q₀ ∈ Q is the start state; F ⊆ Q is the set of accepting (final) states. M accepts a string w if processing w from q₀ leads to a state in F.
The key property of a DFA is determinism: for every state and every input symbol, there is exactly one next state. This makes DFA execution entirely predictable and efficient — recognition runs in linear time in the length of the input.
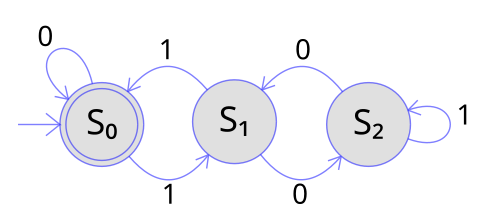
Image: Source
Kleene's Theorem — The Central Result
The most fundamental theorem connecting regular expressions and finite automata is Kleene's Theorem:
A language L is regular (i.e., describable by a regular expression) if and only if there exists a finite automaton that recognises L. Regular expressions and finite automata define exactly the same class of languages — the regular languages.
This equivalence is constructive in both directions: Thompson's construction converts a regex into an NFA; the powerset construction converts an NFA into a DFA; and Arden's Lemma (or state-elimination) converts a DFA back into a regex. Together these algorithms form the backbone of lexical analysis in every modern compiler.
Regular Languages in Practice
Wherever software needs to scan, validate, or tokenise text, regular languages are at work. Lexical analysers (lexers) in compilers use DFAs — automatically generated from regexes — to break source code into tokens. Email validation, IP address parsing, and search-and-replace in text editors all rely on regular expression engines.
- Lexical Analysis: Converting source code into tokens (keywords, identifiers, literals) using DFA-based scanners.
- Pattern Matching:
grep,sed, and text editors use regex engines to find and replace patterns. - Input Validation: Checking that a string is a valid email, URL, phone number, or date format.
- Network Protocols: Protocol parsers recognise fixed-format messages using finite-state machines.
Understanding the formal foundations — what regular expressions truly are, what DFAs compute, and how Kleene's theorem ties them together — gives you the conceptual tools to reason about these tools precisely, rather than treating them as magic.