"A convolutional neural network does not know what a cat is. It knows that certain arrangements of oriented edges, combined with certain color gradients, produce a strong signal in a layer that was trained to say "cat." That turns out to be enough — and surprisingly close to how the visual cortex works."- Claude 2026
Perception and Neural Networks
Perception is the brain's first act of cognition — the conversion of raw sensory signals into meaningful representations. It is also the domain where deep learning has most closely mirrored biological intelligence, and where the gaps between them are most revealing.
Learning objectives
By the end of this page you should be able to:
- Explain perceptual processes in human cognition.
- Describe neural network approaches for image and speech recognition.
- Analyze perception models used in cognitive computing systems.
Perceptual Processes in Human Cognition
Perception is not passive reception — the brain actively constructs a representation of the world, combining incoming signals with prior knowledge. Two opposing flows drive this process:
Bottom-up processing
Perception driven entirely by incoming sensory data — raw edges, luminance contrasts, and frequencies are assembled into higher-level structures. Also called data-driven processing. A standard feedforward neural network is a purely bottom-up system: input flows forward through layers with no influence from expectation or context.
Top-down processing
Perception modulated by prior knowledge, attention, and expectations — the brain fills in ambiguous signals using what it already knows. Reading a sentence with a typo, or recognizing a face in a crowd, both rely on top-down influence. The attention mechanisms in transformers are the closest computational analog.
Beyond these two flows, perception in the brain is organized as a hierarchy of increasingly complex feature detectors: simple elements detected early are progressively combined into richer, more abstract representations at each successive stage. The two sections below trace that hierarchy — first the landmark experiment that revealed it, then the chain of cortical areas it runs through. This same hierarchical organization is what convolutional neural networks later imitate.
Feature detection: Hubel and Wiesel (1959–1962)
Receptive field
Each V1 neuron responds only to stimuli in a specific region of the visual field — at a specific orientation. Not light anywhere; a bar, here, at this angle.
Simple cells
Fire for an oriented edge at a fixed location. Position-specific — move the bar and the response drops. Maps directly onto a CNN's convolutional filters.
Complex cells
Fire for an oriented edge anywhere within a larger region — position-tolerant. First step toward invariant recognition. Maps directly onto CNN pooling layers.
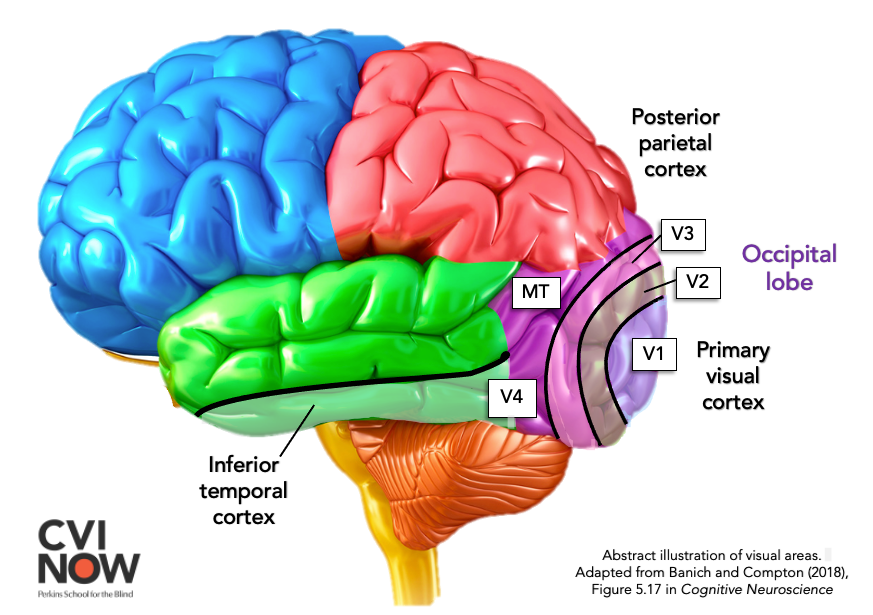
The visual hierarchy
Recording deeper into the visual system revealed that V1 is only the first stage. Signals pass through a chain of cortical areas, each responding to more complex and more position-independent features than the last — culminating in neurons that fire for whole objects regardless of where they appear.
Damage to the inferotemporal cortex (IT) causes visual agnosia: the ability to see, but not to recognize. This local-to-global progression is the template for deep CNN architecture.
Gestalt principles and multisensory integration
Gestalt principles
- Proximity — nearby elements are grouped together
- Similarity — alike elements are seen as belonging together
- Closure — incomplete shapes are completed by the brain
Reflects statistical regularities learned from visual experience. Not captured by standard CNN architectures.
Multisensory integration
- Vision, hearing, touch, and proprioception are combined into a single unified percept
- Each sense is weighted by its reliability in context — vision dominates in good light; touch dominates in darkness
Current AI models process modalities largely in parallel, not in the integrated, context-weighted way the brain does.
Neural Network Approaches: Image Recognition
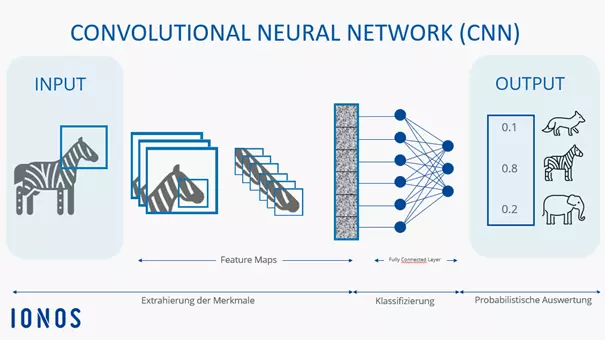
Convolutional Neural Networks (CNNs) translate the Hubel-Wiesel visual hierarchy into learned computation — each layer type has a direct biological counterpart.
Convolutional layers — edge detectors
A small filter (typically 3×3 or 5×5 pixels) slides across the input image, computing a dot product at every position. Each filter learns to detect one local pattern — a vertical edge, a diagonal, a color transition. Early layers learn low-level features exactly as V1 neurons do; deeper layers combine these into complex shapes and object parts, as IT does.
Pooling layers — position tolerance
A max-pooling operation keeps the strongest activation in a small region, discarding exact position. This builds position tolerance into the representation — directly analogous to Hubel and Wiesel's complex cells, which fired for an edge anywhere in their receptive field.
Fully connected layers — classification
After several conv/pool blocks, a flat vector of high-level features feeds into dense layers that map to class probabilities — analogous to the IT cortex's role in object identity, the final stage of the ventral visual stream.
Neural Network Approaches: Speech Recognition
Speech perception in the brain extracts acoustic features — frequency, timing, phoneme boundaries — and routes them toward language areas. Computational speech recognition mirrors this pipeline in three stages.
Spectrogram input
Raw audio is converted into a spectrogram — a 2D representation of frequency content over time. This is the acoustic analog of an image: just as a CNN receives pixel values, a speech model receives spectrogram values. The conversion mirrors the cochlea's role in decomposing sound into frequency components.
Sequence modeling
Unlike images, speech unfolds over time — each phoneme depends on what preceded it. Recurrent networks (RNNs) handle this with hidden state carried forward through time. Transformers handle it with self-attention: every time step can directly attend to any other, capturing long-range dependencies RNNs struggle to maintain.
End-to-end learning
Early systems hand-engineered acoustic features and phoneme boundaries. Modern audio transformer models like Whisper are trained end-to-end directly from spectrograms to text, learning their own internal representations — just as the visual cortex learns its own feature hierarchy from experience.
Where Biology and Computation Converge — and Diverge
CNNs and the visual cortex show striking similarities — and equally striking failures that reveal how the analogy breaks down.
When researchers compared CNN unit activations layer by layer with neural activity recorded from V1, V2, V4, and IT in monkeys shown the same images, they found a strong correspondence: early CNN layers best predicted V1 activity; deeper layers best predicted IT. The network had learned a visual hierarchy similar to the brain's — without being explicitly designed to do so.
CNNs trained on ImageNet are strongly biased toward local texture — a network shown a cat with elephant skin will classify it as an elephant. Humans rely much more on global shape. Despite the architectural similarity, CNNs and the visual cortex solve recognition using somewhat different strategies.
Adversarial examples

An adversarial example is an image modified by imperceptible noise that causes a neural network to misclassify it — while looking completely unchanged to any human.
- Canonical example: a panda classified correctly at 57.7% confidence becomes a gibbon at 99.3% confidence — after adding noise no human can see.
- Why it happens: CNNs learn statistical shortcuts through training data, not the structured, invariant representations biological vision builds.
- Humans are immune: the same perturbation has no effect on human perception — the gap made visible.
- Safety implications: object detectors, medical imaging classifiers, and autonomous vehicle cameras are all potentially vulnerable.
Tools & Tutorials
- CNN Explainer — an interactive, in-browser visualization of a small CNN processing a real image; hover over any neuron to see its receptive field, activations, and the filters it learned. Excellent for building intuition for conv and pooling layers.
- TensorFlow Playground — adjust network depth, activation functions, and learning rate and watch feature representations form in real time; complements CNN Explainer for understanding what layers learn.
- TensorFlow — DeepDream tutorial — a runnable tutorial that uses gradient ascent to visualize what each layer of a CNN has learned to detect, making the feature hierarchy concrete and visible.
Further reading
- Hubel, D. H. & Wiesel, T. N. (1962). Receptive fields, binocular interaction and functional architecture in the cat's visual cortex. The Journal of Physiology, 160(1), 106–154. — the foundational paper establishing the visual feature hierarchy; directly inspired CNN architecture.
- Goodfellow, I., Shlens, J., & Szegedy, C. (2015). Explaining and Harnessing Adversarial Examples. ICLR 2015. — introduces the fast gradient sign method and the panda/gibbon example; essential reading on the limits of CNN perception.
- Yamins, D. L. K. & DiCarlo, J. J. (2016). Using goal-driven deep learning models to understand sensory cortex. Nature Neuroscience, 19(3), 356–365. — reviews the evidence that CNN layer representations correspond to visual cortex areas V1 through IT, and what this convergence implies for both neuroscience and AI.