Deterministic Finite Automata (DFA)
A deterministic finite automaton is the simplest model of a computer: a machine with a finite number of states that reads its input one symbol at a time and transitions between states in a completely predictable way. At any point, the machine is in exactly one state, and each input symbol uniquely determines the next state.
A DFA is a 5-tuple M = (Q, Σ, δ, q₀, F) where Q is a finite set of states, Σ is the input alphabet, δ: Q × Σ → Q is the (total) transition function, q₀ ∈ Q is the start state, and F ⊆ Q is the set of accepting states. M accepts string w if the unique sequence of transitions starting at q₀ ends in a state in F.
The word "deterministic" captures the key constraint: the transition function δ is a function, not a relation — for each (state, symbol) pair there is exactly one outcome. This makes it easy to implement a DFA in software: at each step simply look up the next state in a table.
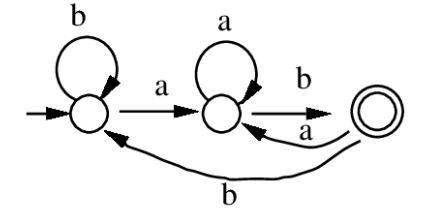
Image: Source
Non-deterministic Finite Automata (NFA)
A non-deterministic finite automaton relaxes the constraint that each (state, symbol) pair maps to exactly one next state. In an NFA, a state may have zero, one, or multiple transitions on the same input symbol. An NFA also permits ε-transitions — state changes that consume no input at all. The machine accepts a string if any sequence of choices leads to an accepting state.
An NFA is a 5-tuple N = (Q, Σ, δ, q₀, F) where the transition function δ: Q × (Σ ∪ {ε}) → 𝒫(Q) maps each (state, symbol) pair to a set of possible next states (the power set of Q). N accepts w if there exists at least one accepting computation path over w.
Non-determinism is a powerful conceptual tool: NFAs are often much smaller and easier to design than equivalent DFAs. For example, constructing an NFA for the language "all binary strings ending in 01" requires only 3 states, while the minimal DFA needs 3 states too — but for more complex patterns the NFA advantage can be exponential in state count.
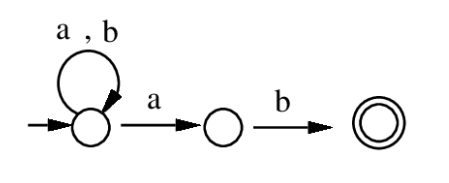
Image: Source
The Equivalence of DFAs and NFAs
Despite their apparent difference in power, DFAs and NFAs recognise exactly the same class of languages — the regular languages. This is one of the most important and surprising results in automata theory.
For every NFA N there exists a DFA D such that L(N) = L(D). Conversely, every DFA is trivially an NFA. Therefore, the class of languages recognised by DFAs equals the class recognised by NFAs.
The Powerset (Subset) Construction
The proof is constructive: given an NFA N with n states, we build a DFA D whose states are the subsets of N's state set. Because the NFA can be in multiple states simultaneously, we track the set of all possible current states as a single DFA state. The resulting DFA has at most 2ⁿ states (one per subset of Q), though in practice many subsets are unreachable and the DFA is often much smaller.
- The DFA start state is the ε-closure of N's start state (all states reachable via ε-transitions from q₀).
- For each DFA state S (a set of NFA states) and each symbol a ∈ Σ, compute the DFA transition: δ_D(S, a) = ε-closure(⋃_{q∈S} δ_N(q, a)).
- A DFA state S is accepting if S ∩ F ≠ ∅ (i.e., it contains at least one NFA accepting state).
- Repeat until no new DFA states are generated.
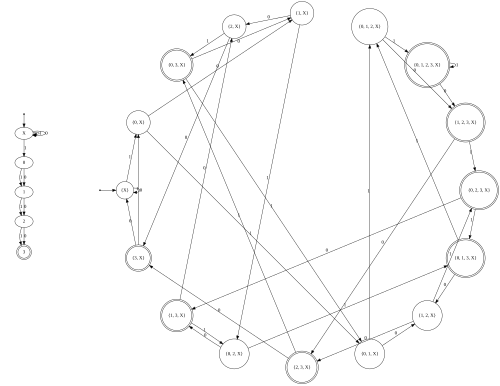
Image: Source
Constructing Automata for Regular Languages
Designing an automaton for a given language requires understanding what information the machine needs to "remember" as it reads the input. Each state encodes a relevant property of the string seen so far. The key questions to ask are: what is the minimum amount of information needed to decide acceptance, and how does each new symbol update that information?
Design Strategies
- Tracking suffixes: To accept strings containing "ab", maintain states that track how much of "ab" has been matched so far (none, "a" seen, "ab" seen).
- Counting modulo k: To accept strings whose length is divisible by k, cycle through k states, one per remainder class.
- Boolean conditions: To enforce that a condition holds throughout, use a "dead" trap state for violation — once entered it cannot be left.
- Product construction: To recognise the intersection of two regular languages L₁ ∩ L₂, build a DFA whose states are pairs (q₁, q₂) from the two individual DFAs.
The equivalence of DFAs and NFAs means you can choose whichever model is more natural for a given design task, and convert afterwards. This flexibility is one of the great practical benefits of the theory.